cpp11及以上新特性学习
1、c++11
1.1、尾返回类型
1 | |
auto在c++11中无法直接作为返回类型,需要使用尾返回类型,在c++14中可以直接使用auto,而不用尾返回类型。这种写法很累赘,因为一般用法在于使用匿名lambda函数时需要返回值,可以这么使用。
1.2、默认模板类型
1 | |
1.3、委托构造函数
1 | |
使用这种形式好处在于如果一个类存在一个公共的初始化需求,比如Person这个基类,name和age这个参数是大家都需要的,就可以把它们抽出来放在一个公共的构造函数里面,需要其他参数的就可以使用委托构造初始化公共部分,然后再初始化自己特定的参数,从而减少不必要的代码。
1.4、final和override
override用于告诉编译器该函数需要重载基类的相同函数,如果没有就会报错,意义在于明确代码中对于该函数的使用意图。
final可以用于终止重载虚函数或者终止继承类。
1.5、枚举类
1 | |
枚举类是为了避免老式枚举和整数之间的隐式转化,导致行为不明确。使用枚举类就可以强制只能在该枚举类中的元素进行对比,变相检查传入参数的类型错误。另外老式的枚举值如果没用限定作用域会造成污染,同一个命名空间定义重复的枚举值会造成编译错误,放在特定的命名空间比较推荐。而枚举类则本身限定了作用域。
1.6、lambda表达式
基本语法
1
2
3auto lambda_example = [捕获列表](参数列表) mutable(可选) 异常属性 -> 返回类型 {
//函数体
}捕获列表两种类型
值捕获
1
2
3
4
5
6int value = 10;
auto handle = [ value ]() {
return value;
};
value = 20;
int value1 = handle();这种情况需要注意拷贝发生在lambda创建时,也就是value =10时,后续value的值发生变化,lambda里面的value也不会发生变化。
1
2
3
4
5
6int value = 10;
auto handle = [ = ]() {
return value;
};
value = 20;
int value1 = handle();“=”表示值捕获当前作用域内lambda表达式之前定义的所有变量,如果变量在lambda创建之后定义的,那么是无法捕获的,会报未定义编译错误。
一般没加mutable关键字的lambda表达式按照值捕获时是无法改变捕获的值,加上mutable之后,就可以在lambda表达式范围内改变该值,并且该值会一直为最新的值而不是刚被捕获时的初始值。但是这个修改不会影响外部的原始的变量。
1
2
3
4
5
6
7int value = 10;
auto lambda1 = [value]() mutable ->int{return ++value;};
std::cout << lambda1() << std::endl; //11
std::cout << lambda1() << std::endl; //12
std::cout << value << std::endl; //10引用捕获
1
2
3
4
5
6int value = 10;
auto handle = [ &value ]() {
return value;
};
value = 20;
int value1 = handle();此时发生引用捕获,当value的值发生变化,lambda里面的value值也会跟着变化。
1
2
3
4
5
6int value = 10;
auto handle = [ & ]() {
return value;
};
value = 20;
int value1 = handle();同理“&”表示引用捕获当前作用域内lambda表达式之前定义的所有变量,如果变量在lambda创建之后定义的,那么是无法捕获的。
1.7、std::function
1 | |
std::function是一个模板函数类型,可以由相同参数类型加返回类型的函数指针或者lambda表达式实例化,然后直接传参调用。现在很多算法api都允许自定义操作,比如std::sort就可以按照自定义规则进行排序,这时候就可以用到std::function。
1.8、std::bind和std::placeholders
1 | |
std::bind作用在于将一个函数配合std::placeholders(占位符)生成一个新的可调用对象。有些情况类似于重载一个默认参数的新版本函数。需要注意的是作用于一个类的成员函数时,需要将对应的类的对象作为第一个参数传递进去。一个常用用法是std::thread需要使用成员函数时,就可以采用std::bind重新生成一个可调用的函数。
1.9、std::move和右值
1 | |
std::move会将一个左值转化为一个右值也就是字面常量,一般用法是当一个对象在本次使用后会释放掉,那么可以使用std::move将它的资源所有权直接转给需要的人,避免拷贝一份。第一次调用push_back时,str拷贝了一份,第二次调用时,str被转化为右值,也就是没有发生拷贝,只是把str对应的资源转移给了vec,这时候str被清空。
1.10、mutable
1 | |
本代码是实现一个线程安全的计数类,value()函数被const修饰,也就是说想要在这个函数里面保证对象内部状态不被修改,但是需要调用互斥锁,这时候使用mutable修饰mutex_就是告诉编译器这个变量不属于该类的内部状态,所以可以修改它。
1.11、atomic
1 | |
atomic是用来在多线程中保证数据同步,可以替代互斥锁,效率更高。但是需要注意的是这个模板类型需要满足trivially-copyable(普通复制)。上述结构体和内置int型都可以使用atomic模板,但是非结构体类型可以进行无锁的原子操作,而结构体类型是有锁的原子操作。atomic模板类可以直接像原始类型一样直接赋值和访问,但是这样是非原子的操作,而使用模板类提供的store()进行赋值操作,和load()进行访问,这两个操作是原子操作。
1 | |
atomic_flag是原子布尔类型,和std::atomic
1.12、enable_shared_from_this
1 | |
这是个模板类,采用奇异递归方式使用,调用shared_from_this()会返回一个弱指针,因此不用造成引用计数+1的问题。使用场景是当A类实例本身被shared_ptr智能指针接管时,如果在A内部成员函数中需要使用这个实例的shared_ptr的参数,这时候如果直接创建一个新的智能指针指托管这个实例,那么就会造成两个智能指针同时托管一个实例,这时就会造成重复释放。
2、c++14
2.1、lambda
右值捕获
1
2
3
4auto u_ptr = std::make_unique<int>(1);
auto handle = [ value= std::move(u_ptr) ]() {
return *value;
};c++11只能捕获左值,c++14可以捕获右值。std::make_unique作为独占指针,当使用std::move转化为右值,u_ptr就失去了资源的所有权变成了一个null(空值)。
泛型
1
2
3
4auto my_lambda = [](auto x, auto y) {
return x + y;
};
auto result = my_lambda(10.1, 11);c++11参数列表类型需要明确,c++14可以使用auto,让编译器去推导参数类型。
3、c++17
3.1、if constexpr
1 | |
if constexpr(折叠表达式)的作用在于编译期确认条件的值,从而在编译器就可以决定进入哪个分支,而不需要在运行期再去判断,提高运行效率。上述代码用于可变长模板解包,如果没有if constexpr 那么就只能采用递归形式一层层分解模板参数个数直到最后一个,就需要额外提供一个终止递归模板函数。
3.2、decomposition declaration
1 | |
分解声明,方便拆解map的key和对应的value,不必去调用它的first和second接口。
4、std常用标准库
4.1、容器
std::array和std::vector
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35void foo(int *p, int size)
{
return;
}
int main(){
std::array<int, 4> arr = {1, 2, 3, 4};//初始化列表
for (auto &v : arr) { //范围for
cout << v << endl;
}
foo(arr.data(), arr.size()); //和c风格数组类型进行转化
std::vector<int> vec = {1, 2, 3, 4};
//vec.reserve(4); //不使用初始化列表时,可以使用reserve预先分配需要的指定大小的内存,避免初始化数据时多次重新分配内存大小。
ulong size = vec.size(); //4
ulong cap = vec.capacity(); //4
vec.push_back(5);
size = vec.size(); //5
cap = vec.capacity(); //8(这里重新分配的机制实际测试时是初始容量大小的两倍)
vec.clear();
size = vec.size(); //0
cap = vec.capacity(); //8
vec.shrink_to_fit(); //将内存大小调整为和实际数据长度一致,可以减少系统内存的使用
size = vec.size(); //0
cap = vec.capacity(); //0
}std::array用于固定大小的数组,用于替代c语言的指针数组,std::vector作为动态数组,会根据初始化值事先分配一个内存大小,而不是每次都插入数据都重新分配内存大小,只有当数据长度大于预分配的内存大小才会重新分配内存大小。当删除其中的元素时也不会释放对应的内存,需要手动调用shrink_to_fit()。
std::map和std::unordered_map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22std::map<int, std::string> map = {{1, "1"}, {3, "3"}, {2, "2"}};
for (auto &[key, value] : map) {
cout << key << ":" << value << endl;
}
/*
*1:1
*2:2
*3:3
*/
std::unordered_map<int, std::string> unorderer_map = {{1, "1"}, {3, "3"}, {2, "2"}};
for (auto &[key, value] : unorderer_map) {
cout << key << ":" << value << endl;
}
/*
*2:2
*3:3
*1:1
*/std::map作为有序容器,使用平衡二叉树(例如红黑树)实现,会按照key进行排序,而std::unordered_map是无序容器,采用hash表实现,不会进行排序。无序容器在插入和查询数据时效率比有序容器大幅度提高,但是无序容器会需要额外的内存存储哈希表,比有序容器消耗更多的内存。所以需要使用map时,如果不考虑顺序和内存占用,尽量采用无序容器。
std::list和std::forward_list
1
2
3
4
5
6
7
8
9std::forward_list<int> for_list{1, 2, 3, 4, 10, 11, 12, 13};
for_list.remove_if(std::bind(std::less<int>(), std::placeholders::_1, 10));//删除小于10的元素
for (auto &value : for_list) {
cout << value << endl;
}
auto size = std::distance(std::begin(for_list), std::end(for_list));std::list是双向链表,而std::forward_list是单向链表,所以少了很多操作接口,比如没有back()返回最后一个元素引用。同时也没有size()返回大小,需要配合std::distance计算大小。std::forward_list优势是内存占用小,插入效率高。
std::tuple
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18char char_value;
double double_value;
std::tuple< char, double> tuple1{'t', 10.02};
cout << std::get<char>(tuple1) << endl;//以数据类型作为模板参数获取对应的值,但是需要注意如果存在多个相同类型的值就无法获取,会产生编译错误
cout << std::get<0>(tuple1) << endl;//以下标为模板参数,但是需要是一个编译期确定的常量。
std::tie(char_value, double_value) = tuple1;//c++11使用std::tie解析数据
std::cout << char_value << ";" << double_value << endl;
std::tuple<int, std::string, bool> tuple2;
tuple2 = std::make_tuple(10, "tuple", false);
std::tuple tuple3 = std::tuple_cat(tuple1, tuple2);//拼接两个tuple
auto &[char_value1, double_value1, int_value, string_value, bool_value] = tuple3;//c++17中可以类似python结构化绑定,需要注意[]中的变量不能是已经定义过的,不然会导致重定义。
auto tuple_size = std::tuple_size< decltype(tuple3)>::value;//计算大小
cout << tuple_size << endl;std::tuple(元组)作用在于将任意个数的数据绑定为一个整体,是一个轻量化数据结构体,类似std::pair的升级版,std::pair只能绑定两个数据。
5、内存管理
5.1、RAII
c++11之前一般内存管理比较常用的模式RAII,总体思路就是构造函数中初始化资源,在析构函数中释放资源。
1 | |
上面是一个简单的模板RAII实现,可以构造任意类型的数据并防止拷贝,没有考虑多线程等因素。
5.2、智能指针
c++11引入了三个智能指针,std::shared_ptr,std::weak_ptr和std::unique_ptr,是RAII的标准库实现,用于去掉显示的new和delete,自动管理内存的创建和释放。
1 | |
std::unique_ptr
独占指针,指针之间无法互相拷贝,但是可以通过std::move将前一个指针转为右值给新的指针,前一个指针的数据被清空,适合用完之后退出作用域就释放的场景。
std::weak_ptr和std::shared_ptr
std::shared_ptr采用引用计数,当引用计数为0时就会释放对应的内存,但是存在一个循环引用的问题(常见于观察者模式和双向链表),导致即使智能指针在离开作用域销毁时也无法释放内存。std::weak_ptr(弱引用指针)作为这种情况的一个补充用于解决这种问题。std::weak_ptr无法单独使用,不能直接通过裸指针创建,需要基于std::shared_ptr通过拷贝的方式创建,但是不会增加原本的std::shared_ptr的引用计数。std::weak_ptr无法直接访问裸指针,需要通过lock()获取对应的std::shared_ptr,再间接访问裸指针。如果裸指针已经被释放,会返回null。这个接口是线程安全。
循环引用及解决方案代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class B;
class A
{
public:
std::shared_ptr<B> pointer;
};
class B
{
public:
std::shared_ptr<A> pointer;
//std::weak_ptr<A> pointer; 解决办法
};
int main()
{
std::shared_ptr<A> ptr_a = std::make_shared<A>();
std::shared_ptr<B> ptr_b = std::make_shared<B>();
ptr_a->pointer = b;
ptr_b->pointer = a;
}前后引用关系如下图:
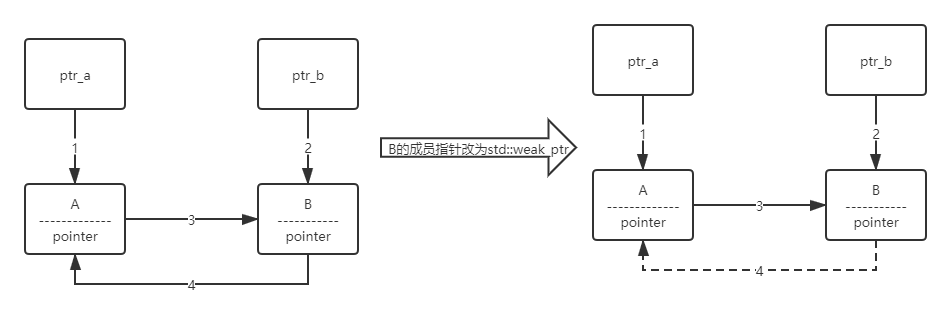
将B中对于A的引用改为std::weak_ptr之后,ptr_a和ptr_b释放时会断掉1和2的引用,随后A因为引用计数为0先释放,然后B接着释放。